M-x set-buffer-file-coding-system RET unix
Thursday, September 29, 2011
Changing end of line in Emacs
http://mike.kruckenberg.com/archives/2004/08/replace_m_in_em.html
Friday, September 23, 2011
Facebook Python code for OAuth2
Facebook recently announced that on October 1st, 2011, all Facebook third-party apps will need to transition to OAuth2. The JavaScript and PHP SDK code is posted, but how would you make the change if you're using Python/Django? To help others make the transition, we've released our own set of Python code at this GitHub repo:
https://github.com/rogerhu/facebook_oauth2
One of the pain points is that users may have existing OAuth cookies set on their browser, which you may use in your current application to authenticate. However, because Facebook Connect's JavaScript library requires an apiKey change parameter, it makes it hard to use their existing library to force these fbs_ cookie deletions. Furthermore, you'd have to write your own JS since the Facebook JS SDK is hard-coded to use only the new apiKey parameter.
We also show in this code how you can force these fbs_ cookie deletions on the server-side, primarily by setting the expiration date and providing the correct domain= parameter back to the client. It's worked well for us in managing the transition to OAuth2, so we hope you will find the same approach useful.
Good luck!
https://github.com/rogerhu/facebook_oauth2
One of the pain points is that users may have existing OAuth cookies set on their browser, which you may use in your current application to authenticate. However, because Facebook Connect's JavaScript library requires an apiKey change parameter, it makes it hard to use their existing library to force these fbs_ cookie deletions. Furthermore, you'd have to write your own JS since the Facebook JS SDK is hard-coded to use only the new apiKey parameter.
We also show in this code how you can force these fbs_ cookie deletions on the server-side, primarily by setting the expiration date and providing the correct domain= parameter back to the client. It's worked well for us in managing the transition to OAuth2, so we hope you will find the same approach useful.
Good luck!
Wednesday, September 21, 2011
Lessons Learned: Migrating Tests to Selenium v2
The slides from yesterday's talk, Lessons Learned: Migrating Tests to Selenium v2, are now posted. Remember the game Simon Says? Check out the game Hearsay Social Says, which shows how Selenium v2 can be used to automate web browser testing.
Saturday, September 17, 2011
How Selenium v1 bypasses cross-origin domain security policies...
The writeup by Simon Stewart from the Architecture of Open Source Applications discusses how the architecture of Selenium v2 was guided by the lessons drawn from Selenium 1. The figures and discussions on the Selenium http://seleniumhq.org/docs/05_selenium_rc.html also mention the fact that a proxy-server is used to get past cross-domain security policies. But how does Selenium v1 work under the covers?
Here's the general steps of what happens when you go from launching a Selenium RC (v1) server.
Suppose you wrote this Python script (let's call test1.py) on your local Linux box and launched a Selenium RC server on a Windows 7 machine.
 1. The Selenium RC server starts and waits for an HTTP connection from a client. When the client connects and sends an instruction to initiate new Selenium instance, the Selenium RC server will launch the browser and configure the browser's proxy settings.
1. The Selenium RC server starts and waits for an HTTP connection from a client. When the client connects and sends an instruction to initiate new Selenium instance, the Selenium RC server will launch the browser and configure the browser's proxy settings.
 2. Selenium v1 JavaScript code is also loaded into the browser. This JavaScript code is what is used by Selenium for performing all its automated testing (i.e. used to query DOM elements, generate mouse clicks, etc.). You can click View Source on the Selenium RC tab to see what JavaScript code is loaded.
2. Selenium v1 JavaScript code is also loaded into the browser. This JavaScript code is what is used by Selenium for performing all its automated testing (i.e. used to query DOM elements, generate mouse clicks, etc.). You can click View Source on the Selenium RC tab to see what JavaScript code is loaded.
 Note that there's also a runTest() JavaScript command executed when this page is loaded. When this happens, an Ajax connection is also initiated in selenium-remoterunner.js:
Note that there's also a runTest() JavaScript command executed when this page is loaded. When this happens, an Ajax connection is also initiated in selenium-remoterunner.js:
3. The RC server then opens a URL connection specified by the client API with a /selenium-server/core/Blank.html?start=true. (Note that when creating a Selenium instance, a specific URL must also be provided.) If this connection was successful, it also helps to verify that the proxy configuration was setup properly.

4. What happens if this Ajax connection from the browser to the RC server times out? If the request timeouts (i.e. no command), another Ajax request is sent and the channel is re-established. This is performed within the selenium-executionloop.js, which initiates a new Ajax connection back to the Selenium server.
6. When this communication channel is setup, Selenium clients sending an v1 API command will be sent to the server, which in turns relays the communicate on this Ajax channel to send/receive commands. Selenium v1 relies on JavaScript to simulate all browser interactions, and the appropriate command is executed.
Selenium v2 avoids this issue entirely by using native drivers that bind tightly to the operating system...but this approach introduces new issues and complexities, which will be discussed in this week's upcoming Meetup.com event.
Here's the general steps of what happens when you go from launching a Selenium RC (v1) server.
Suppose you wrote this Python script (let's call test1.py) on your local Linux box and launched a Selenium RC server on a Windows 7 machine.
from selenium import selenium selenium = selenium(“10.10.10.1", 4444, "*iexplore", "http://www.google.com/") selenium.start() selenium.open(“/”)



nextCommand: function () {this.xmlHttpForCommandsAndResults = XmlHttp.create();
sendToRC(postResult, urlParms, fnBind(this._HandleHttpResponse, this), this.xmlHttpForCommandsAndResults);
};
During the configuration of this proxy, all /selenium-server URL's are intercepted and routed to the RC server. By using an Ajax connection that uses the same URL as the one that is being tested, Selenium v1 can therefore avoid triggering browser cross-domain security policies and establish establish a connection back to the Selenium RC server to sending/receiving future commands. You'll notice how this browser proxy configuration works if you tried to add a /selenium-server to any URL (i.e. http://www.google.com/selenium-server would normally return back a Page Not Found error).3. The RC server then opens a URL connection specified by the client API with a /selenium-server/core/Blank.html?start=true. (Note that when creating a Selenium instance, a specific URL must also be provided.) If this connection was successful, it also helps to verify that the proxy configuration was setup properly.
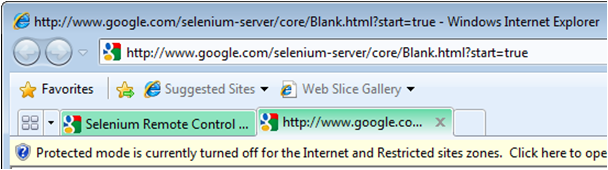
4. What happens if this Ajax connection from the browser to the RC server times out? If the request timeouts (i.e. no command), another Ajax request is sent and the channel is re-established. This is performed within the selenium-executionloop.js, which initiates a new Ajax connection back to the Selenium server.
continueTest : function() {LOG.debug("currentTest.continueTest() - acquire the next command");
if (! this.aborted) {
this.currentCommand = this.nextCommand();
}
6. When this communication channel is setup, Selenium clients sending an v1 API command will be sent to the server, which in turns relays the communicate on this Ajax channel to send/receive commands. Selenium v1 relies on JavaScript to simulate all browser interactions, and the appropriate command is executed.
Selenium v2 avoids this issue entirely by using native drivers that bind tightly to the operating system...but this approach introduces new issues and complexities, which will be discussed in this week's upcoming Meetup.com event.
Tuesday, September 13, 2011
BeautifulSoup v4
See this warning msg?
bs4/builder/_html5lib.py:60: DataLossWarning: namespaceHTMLElements not supported yet
DataLossWarning)
bs4/builder/_html5lib.py:77: DataLossWarning: BeautifulSoup cannot represent elements in any namespace
warnings.warn("BeautifulSoup cannot represent elements in any namespace", DataLossWarning)
Apparently here is the reason for this msg:
https://bugs.launchpad.net/beautifulsoup/+bug/727014
Leonard Richardson (leonardr) wrote on 2011-03-01: #1
html5lib supports namespaced elements (like), and Beautiful Soup doesn't yet. These warnings are mostly a reminder to myself that I need to add namespace support. Unless you're actually parsing code that has namespaced tags, there won't be any real data loss.
Changed in beautifulsoup:
status: New → Confirmed
bs4/builder/_html5lib.py:60: DataLossWarning: namespaceHTMLElements not supported yet
DataLossWarning)
bs4/builder/_html5lib.py:77: DataLossWarning: BeautifulSoup cannot represent elements in any namespace
warnings.warn("BeautifulSoup cannot represent elements in any namespace", DataLossWarning)
Apparently here is the reason for this msg:
https://bugs.launchpad.net/beautifulsoup/+bug/727014
Leonard Richardson (leonardr) wrote on 2011-03-01: #1
html5lib supports namespaced elements (like
Changed in beautifulsoup:
status: New → Confirmed
lxml and removing nodes
The lxml library for Python represents a really effective tool for parsing and manipulating XML-based data. You can manipulate the XML documents to deal with the W3C standards for Inclusive and Exclusive Canonicalization, which deals with all messy details of adjusting namespaces as you extract sections of the data.
XML is inherently a difficult data structure to manipulate. The white spaces, return lines, and new lines make a big difference in validating signatures and/or digest values. If you accidentally miss a character in your text manipulation, perform the wrong canonicalization, etc. your one-way SHA hash can easily be affected, causing you to be unable to verify the signature of the data.
One of the idiosyncracies of the lxml library, described best in this lxml document, is that the internal data structures are stored as Element objects with a .text and .tail property. The .text represents all the underlying value within the tag, while the .tail property represents the text between tags. This data structure differs from the DOM-model in that the text after an element is represented by the parent. For example, consider this XML-structure:
<a>aTEXT
<b>bTEXT</b>bTAIL
</a>aTAIL
This can be represented with the following lxml code:
What happens if you remove the 'b' node? Ideally, the text with the 'b' tag disappears, while the bTAIL gets moved up. The structure would look like the following:
<a>aTEXTbTAIL</a>aTAIL
The command to remove the lxml node would be:
Upon making this change, however, it appears in lxml v2.3, the output appeared as: <a>aTEXT</a>aTAIL</a>
In order to understand what's going on, I had to download the source for the lxml, install the Cython library that converts the .pyx code to .C bindings, recompile, and link the new etree.so binary. If you're curious, the instructions for doing so here are posted here.
Upon inspecting the etree.pyx, I noticed the code to move the tail occured after unlinking the node. What we really wanted is that the tail to be moved before the node is unlinked. Otherwise, the information about the tail would also be potentially be removed, which may have explained why the tail was never copied.
Examining the _moveTail code also points to something interesting. The .tail is represented internally by XML-based text-based nodes, which are siblings of the current node (denoted by the .next pointer). Text nodes are also XML-based text-nodes, but appear to be children of the node. There is a loop that traverses the linked list of nodes, such that there can be multiple text-nodes, which could could happen if multiple subelements were removed, and you were left with a chain of XML-based .tail nodes.
Upon fixing this code, the text_xinclude_test started failing. If I recompiled and reverted back to the original etree.pyx, the test passed fine. One even more unusual aspect was the invocation of the self.include(), which appeared to be overriden depending on whether the lxml library would rely on the native implementation of the xinclude() routine, or rely on its Python-based version that allows external URL's to referenced in ElementInclude.py.
The test_xinclude_text() is a routine to verify that one can use <:xi:include> directives to incorporate other files within an XML-document. When such a tag is discovered, the contents of the file is read (in this case, the contents of test_broken.xml) and the entire node is substituted with this text. The parent node's .text property will then be set and the <xi:include> is removed.
It appears that code within the ElementInclude.py the text appeared to mask this issue by appending the tail before removing it:
The entire pull request for this fix is located here:
https://github.com/lxml/lxml/pull/14/files
Update on this PR:
Note that this is a deliberate design choice. It will not change.
http://lxml.de/FAQ.html#what-about-that-trailing-text-on-serialised-elements
http://lxml.de/tutorial.html#elements-contain-text
In other words, if you remove a subelement, you have to take care of the .tail and move it to the right tag. The lxml library will not change so this PR request was rejected.
XML is inherently a difficult data structure to manipulate. The white spaces, return lines, and new lines make a big difference in validating signatures and/or digest values. If you accidentally miss a character in your text manipulation, perform the wrong canonicalization, etc. your one-way SHA hash can easily be affected, causing you to be unable to verify the signature of the data.
One of the idiosyncracies of the lxml library, described best in this lxml document, is that the internal data structures are stored as Element objects with a .text and .tail property. The .text represents all the underlying value within the tag, while the .tail property represents the text between tags. This data structure differs from the DOM-model in that the text after an element is represented by the parent. For example, consider this XML-structure:
<a>aTEXT
<b>bTEXT</b>bTAIL
</a>aTAIL
This can be represented with the following lxml code:
import etree
a = etree.Element('a')
a.text = "aTEXT"
a.tail = "aTAIL"
b = SubElement(a, 'b')
b.text = "bTEXT"
b.tail = "bTAIL"
What happens if you remove the 'b' node? Ideally, the text with the 'b' tag disappears, while the bTAIL gets moved up. The structure would look like the following:
<a>aTEXTbTAIL</a>aTAIL
The command to remove the lxml node would be:
a.remove(b)
Upon making this change, however, it appears in lxml v2.3, the output appeared as: <a>aTEXT</a>aTAIL</a>
In order to understand what's going on, I had to download the source for the lxml, install the Cython library that converts the .pyx code to .C bindings, recompile, and link the new etree.so binary. If you're curious, the instructions for doing so here are posted here.
Upon inspecting the etree.pyx, I noticed the code to move the tail occured after unlinking the node. What we really wanted is that the tail to be moved before the node is unlinked. Otherwise, the information about the tail would also be potentially be removed, which may have explained why the tail was never copied.
def remove(self, _Element element not None):
- tree.xmlUnlinkNode(c_node)
_moveTail(c_next, c_node)
+ tree.xmlUnlinkNode(c_node)
Examining the _moveTail code also points to something interesting. The .tail is represented internally by XML-based text-based nodes, which are siblings of the current node (denoted by the .next pointer). Text nodes are also XML-based text-nodes, but appear to be children of the node. There is a loop that traverses the linked list of nodes, such that there can be multiple text-nodes, which could could happen if multiple subelements were removed, and you were left with a chain of XML-based .tail nodes.
cdef void _moveTail(xmlNode* c_tail, xmlNode* c_target):
cdef xmlNode* c_next
# tail support: look for any text nodes trailing this node and
# move them too
c_tail = _textNodeOrSkip(c_tail)
while c_tail is not NULL:
c_next = _textNodeOrSkip(c_tail.next)
tree.xmlUnlinkNode(c_tail)
tree.xmlAddNextSibling(c_target, c_tail)
c_target = c_tail
c_tail = c_next
Upon fixing this code, the text_xinclude_test started failing. If I recompiled and reverted back to the original etree.pyx, the test passed fine. One even more unusual aspect was the invocation of the self.include(), which appeared to be overriden depending on whether the lxml library would rely on the native implementation of the xinclude() routine, or rely on its Python-based version that allows external URL's to referenced in ElementInclude.py.
def test_xinclude_text(self):
filename = fileInTestDir('test_broken.xml')
root = etree.XML(_bytes('''\
''' % filename))
old_text = root.text
content = read_file(filename)
old_tail = root[0].tail
self.include( etree.ElementTree(root) )
self.assertEquals(old_text + content + old_tail,
root.text)
The test_xinclude_text() is a routine to verify that one can use <:xi:include> directives to incorporate other files within an XML-document. When such a tag is discovered, the contents of the file is read (in this case, the contents of test_broken.xml) and the entire node is substituted with this text. The parent node's .text property will then be set and the <xi:include> is removed.
It appears that code within the ElementInclude.py the text appeared to mask this issue by appending the tail before removing it:
@@ -204,7 +204,8 @@ def _include(elem, loader=None, _parent_hrefs=None, base_url=None):
elif parent is None:
return text # replaced the root node!
else:
- parent.text = (parent.text or "") + text + (e.tail or "")
+ parent.text = (parent.text or "") + text
parent.remove(e)
The entire pull request for this fix is located here:
https://github.com/lxml/lxml/pull/14/files
Update on this PR:
Note that this is a deliberate design choice. It will not change.
http://lxml.de/FAQ.html#what-about-that-trailing-text-on-serialised-elements
http://lxml.de/tutorial.html#elements-contain-text
In other words, if you remove a subelement, you have to take care of the .tail and move it to the right tag. The lxml library will not change so this PR request was rejected.
Monday, September 12, 2011
Compiling and testing lxml2..
The instructions for recompiling lxml seem pretty straightforward. You have to pip install Cython, which is used to convert the .pyx file into a .c file, which then can be gcc compiled. The libxml2-dev and libxslt-dev must be packaged installed.
http://lxml.de/1.3/build.html
If you want to test that the unit tests still pass, you can link the uld type:
http://lxml.de/1.3/build.html
git clone https://github.com/lxml/lxml/ sudo apt-get install libxml-dev sudo apt-get install libxslt-dev pip install Cython python setup.py build_ext
If you want to test that the unit tests still pass, you can link the uld type:
cd src/lxml ln -s ../../build/lib.linux-x86_64-2.6/lxml/etree.so cd ../.. python test.py test_etree.py
Friday, September 9, 2011
lxml
One of the best documentation for using lxml in Python is located here:
infohost.nmt.edu/tcc/help/pubs/pylxml/pylxml.pdf
One interesting tidbit:
In the DOM, trees are build out of nodes represented as Node instances. Some nodes are Element instances, representing whole elements. Each Element has an assortment of child nodes of various types: Element nodes for its element children; Attribute nodes for its attributes; and Text nodes for textual content.
The lxml view of an XML document, by contrast, builds a tree of only one node type: the Element.
The text following the element. This is the most unusual departure. In the DOM model, any text
following an element E is associated with the parent of E; in lxml, that text is considered the “tail” of E.
infohost.nmt.edu/tcc/help/pubs/pylxml/pylxml.pdf
One interesting tidbit:
In the DOM, trees are build out of nodes represented as Node instances. Some nodes are Element instances, representing whole elements. Each Element has an assortment of child nodes of various types: Element nodes for its element children; Attribute nodes for its attributes; and Text nodes for textual content.
The lxml view of an XML document, by contrast, builds a tree of only one node type: the Element.
The text following the element. This is the most unusual departure. In the DOM model, any text
following an element E is associated with the parent of E; in lxml, that text is considered the “tail” of E.
Thursday, September 1, 2011
Subscribe to:
Comments (Atom)